memory management
在stackoverflow上看到一个非常有意思的问题: Why is transposing a matrix of 512×512 much slower than transposing a matrix of 513×513 ?
原文地址: https://stackoverflow.com/questions/11413855/why-is-transposing-a-matrix-of-512x512-much-slower-than-transposing-a-matrix-of
SMP: 对称多处理系统内有许多紧耦合多处理器,在这样的系统中,所有的CPU共享全部资源,如总线,内存和I/O系统等. 这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。操作系统管理着一个队列,每个处理器依次处理队列中的进程。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。
非常好的文章, 感谢作者! 本文章转自: https://strikefreedom.top/linux-io-and-zero-copy (侵删!)
raft算法一个非拜占庭的一致性算法, 即所有通信是正确的而非伪造的. N 个结点的情况下(N为奇数)可以最多容忍 (N-1)/2 个结点故障.
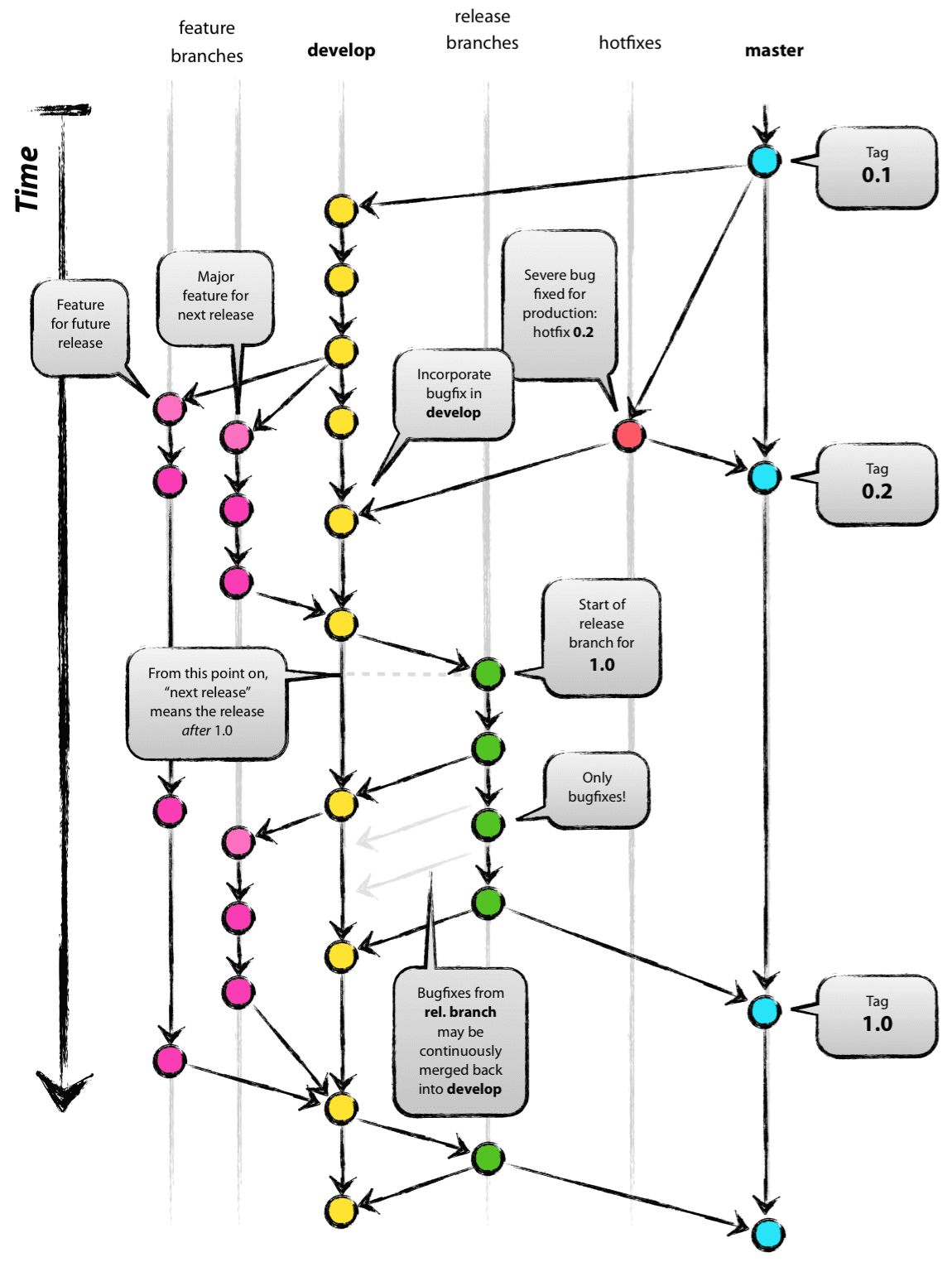
1、开发流程图
做之前需要清理一下ceph原有的配置: ceph-deploy purge SH-IDC1-10-121-2-165 SH-IDC1-10-121-2-167 SH-IDC1-10-121-2-169 ceph-deploy purgedata SH-IDC1-10-121-2-165 SH-IDC1-10-121-2-167 SH-IDC1-10-121-2-169 ——————————————————————————————- #mons ceph-deploy new SH-IDC1-10-121-2-165 SH-IDC1-10-121-2-167 SH-IDC1-10-121-2-169
当前操作基于ceontos
以下每一个标题为一个单独的知识点
