rgw lifecycle
1. 集群环境说明
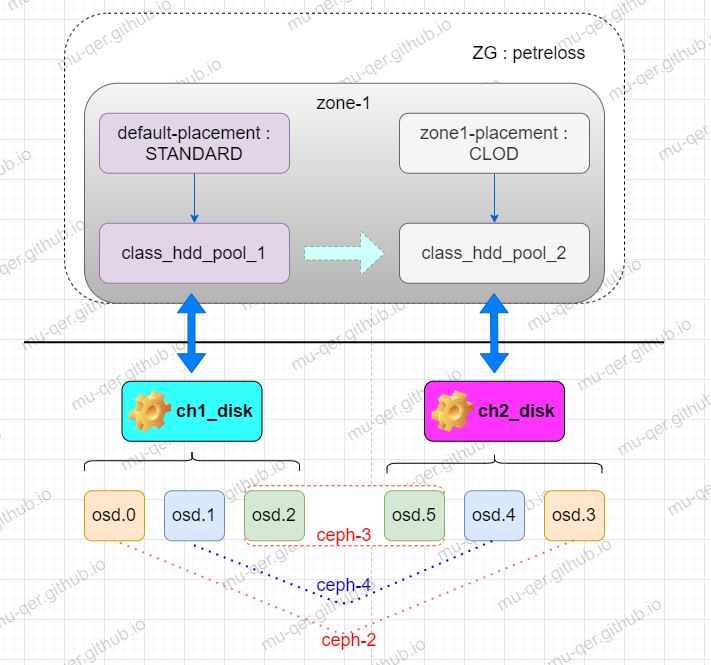
三台机器, 部署nautilus版本(关于在线部署请看另一篇文章:ceph-ansible部署nautilus版本ceph集群):
- ceph-2: 192.168.2.76 (部署 mons, mgrs, osds), (osd0, 0sd3)
- ceph-3: 192.168.2.27 (部署 mons, osds, rgws), (osd2, osd5)
- ceph-4: 192.168.2.40 (部署 mons, osds, rgws), (osd1, osd4)
2.修改crushmap
初始的crushmap如下:
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29398 root default
-3 0.09799 host ceph-2
0 hdd 0.04900 osd.0 up 1.00000 1.00000
3 hdd 0.04900 osd.3 up 1.00000 1.00000
-7 0.09799 host ceph-3
2 hdd 0.04900 osd.2 up 1.00000 1.00000
5 hdd 0.04900 osd.5 up 1.00000 1.00000
-5 0.09799 host ceph-4
1 hdd 0.04900 osd.1 up 1.00000 1.00000
4 hdd 0.04900 osd.4 up 1.00000 1.00000
需要在同一个zone中实现lifecycle,需要将三组host对应是osds进行划分,划分的规则就是:同一组主机的osd分别用于划分不同是pool。划分完后,crushmap如下:
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-17 0.44696 root ch2_disk
-5 0.14899 host ceph-2-3
3 hdd 0.04900 osd.3 up 1.00000 1.00000
-13 0.14899 host ceph-3-5
5 hdd 0.04900 osd.5 up 1.00000 1.00000
-9 0.14899 host ceph-4-4
4 hdd 0.04900 osd.4 up 1.00000 1.00000
-15 0.44696 root ch1_disk
-3 0.14899 host ceph-2-0
0 hdd 0.04900 osd.0 up 1.00000 1.00000
-11 0.14899 host ceph-3-2
2 hdd 0.04900 osd.2 up 1.00000 1.00000
-7 0.14899 host ceph-4-1
1 hdd 0.04900 osd.1 up 1.00000 1.00000
具体的划分步骤如下:(目前还不会使用命令行修改, 以后会补充一份命令行的修改过程)
- 获取crush map
ceph osd getcrushmap -o crushmap - 使用 crushtool 进行反编译 crush map
crushtool -d crushmap -o dencode_crushmap - 修改dencode_crushmap 文件:
# buckets
#--------------------------------------------------------------#
# 将单个osd独立划分成对应的 host, 以便于下边规则添加按host进行
#--------------------------------------------------------------#
host ceph-2-0 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.049
}
host ceph-2-3 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.049
}
host ceph-4-1 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.049
}
host ceph-4-4 {
id -9 # do not change unnecessarily
id -10 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item osd.4 weight 0.049
}
host ceph-3-2 {
id -11 # do not change unnecessarily
id -12 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.049
}
host ceph-3-5 {
id -13 # do not change unnecessarily
id -14 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item osd.5 weight 0.049
}
# root
#------------------------------------------------------------#
# 将独立的host按约定划分成两组,并为这两组创建规则 rule
#------------------------------------------------------------#
root ch1_disk {
id -15 # do not change unnecessarily
id -16 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item muhongtao-ceph-2-0 weight 0.149
item muhongtao-ceph-3-2 weight 0.149
item muhongtao-ceph-4-1 weight 0.149
}
root ch2_disk {
id -17 # do not change unnecessarily
id -18 class hdd # do not change unnecessarily
alg straw2
hash 0 # rjenkins1
item muhongtao-ceph-2-3 weight 0.149
item muhongtao-ceph-3-5 weight 0.149
item muhongtao-ceph-4-4 weight 0.149
}
# rules
#------------------------------------------------------------#
# 为这两组root 创建规则 rule
#------------------------------------------------------------#
rule ch1_disk {
id 0
type replicated
min_size 1
max_size 10
step take ch1_disk
step chooseleaf firstn 0 type host
step emit
}
rule ch2_disk {
id 1
type replicated
min_size 1
max_size 10
step take ch2_disk
step chooseleaf firstn 0 type host
step emit
}
#end crush map
- 编译新的crush map
crushtool -c dencode_crushmap -o newcrushmap
- 将crush map注入当前集群环境
ceph osd setcrushmap -i newcrushmap
3.创建pool
删除无用的pool,并在这两个ch1_disk/ch2_disk规则之上创建新的pool
3.1删除default pool, 只剩下 .rgw.root
运行 ./clean_pool.sh default
#clean_pool.sh
#!/bin/bash
pool_prefix=$1
all_pool=`ceph osd pool ls|grep ${pool_prefix}`
echo "all_pool:${all_pool}"
for cur_pool in ${all_pool}
do
ceph osd pool delete ${cur_pool} ${cur_pool} --yes-i-really-really-mean-it
done
3.2创建两大类新的pool
创建两大类pool: class_hdd_pool_1.xxx 和 class_hdd_pool_2.xxx 其中, class_hdd_pool_1.xxx 用于 STANDARD 存储类, class_hdd_pool_2.xxx 用于 CLOD 存储类. 在生命周期服务中, transition 操作是将 存储类A 中的data pool中的数据转移至 存储类B 中的data pool 中。 而其他元数据/索引数据将共用 存储类A的。
- class_hdd_pool_1.xxx
- class_hdd_pool_1.data
- class_hdd_pool_1.index
- class_hdd_pool_1.control
- class_hdd_pool_1.meta
- class_hdd_pool_1.log
- class_hdd_pool_1.non-ec
- class_hdd_pool_2.xxx
- class_hdd_pool_2.data
- class_hdd_pool_2.index
- class_hdd_pool_2.control
- class_hdd_pool_2.meta
- class_hdd_pool_2.log
- class_hdd_pool_2.non-ec
#build_2class_pool.sh
#!/bin/bash
classpool_prefix="class_hdd_pool_"
id=1
end_id=3
while true
do
if [ ${id} -eq ${end_id} ];then
break
fi
pool_name=${classpool_prefix}${id}
#使用对应的rule
rule_name=ch${id}_disk
echo "pool_name:${pool_name} rule_name:${rule_name}"
#create pool, pg/pgp 需自行修改
ceph osd pool create ${pool_name}.data 64 64 replicated ${rule_name}
ceph osd pool create ${pool_name}.index 16 16 replicated ${rule_name}
ceph osd pool create ${pool_name}.control 8 8 replicated ${rule_name}
ceph osd pool create ${pool_name}.meta 8 8 replicated ${rule_name}
ceph osd pool create ${pool_name}.log 8 8 replicated ${rule_name}
ceph osd pool create ${pool_name}.non-ec 8 8 replicated ${rule_name}
let id=${id}+1
done
- 运行 ./build_2class_pool.sh 创建pool
- 查看pool
[root@ceph-3 storage-class]# ceph osd pool ls
.rgw.root
class_hdd_pool_1.data
class_hdd_pool_1.index
class_hdd_pool_1.control
class_hdd_pool_1.meta
class_hdd_pool_1.log
class_hdd_pool_1.non-ec
class_hdd_pool_2.data
class_hdd_pool_2.index
class_hdd_pool_2.control
class_hdd_pool_2.meta
class_hdd_pool_2.log
class_hdd_pool_2.non-ec
[root@ceph-3 storage-class]# ceph -s
cluster:
id: 7a03beb1-268b-4f5d-af43-0feabc4c7022
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-4,ceph-2,ceph-3 (age 6h)
mgr: ceph-3(active, since 17h)
osd: 6 osds: 6 up (since 2h), 6 in (since 17h)
rgw: 2 daemons active (ceph-2.rgw0, ceph-4.rgw0)
task status:
data:
pools: 13 pools, 256 pgs
objects: 12 objects, 2.1 KiB
usage: 6.3 GiB used, 294 GiB / 300 GiB avail
pgs: 256 active+clean
4. 创建realm, zg, zone
4.1 创建realm, zg, zone及zong1-placement
#delete default zg/zong
radosgw-admin zonegroup delete --rgw-zonegroup=default
radosgw-admin zone delete --rgw-zone=default
#create realm,zg,zone
radosgw-admin realm create --rgw-realm=petrel --default
radosgw-admin zonegroup create --rgw-zonegroup=petreloss --rgw-realm=petrel --master --default
radosgw-admin zone create --rgw-zone=zone1 --rgw-zonegroup=petreloss --master --default
radosgw-admin zone set --rgw-zone=zone1 --master --default --infile zone1.json
radosgw-admin period update --commit
由于这个实验是在同一个zone中的两个pool之间进行lifecycle的, 因此zone1的标准存储类别STANDARD使用的pool限定在class_hdd_pool_1中, zone1的冷存CLOD使用的pool限定在class_hdd_pool_2中。
其中zone1.json文件内容如下,
{
"name": "zone1",
"domain_root": "class_hdd_pool_1.meta:root",
"control_pool": "class_hdd_pool_1.control",
"gc_pool": "class_hdd_pool_1.log:gc",
"lc_pool": "class_hdd_pool_1.log:lc",
"log_pool": "class_hdd_pool_1.log",
"intent_log_pool": "class_hdd_pool_1.log:intent",
"usage_log_pool": "class_hdd_pool_1.log:usage",
"reshard_pool": "class_hdd_pool_1.log:reshard",
"user_keys_pool": "class_hdd_pool_1.meta:users.keys",
"user_email_pool": "class_hdd_pool_1.meta:users.email",
"user_swift_pool": "class_hdd_pool_1.meta:users.swift",
"user_uid_pool": "class_hdd_pool_1.meta:users.uid",
"system_key": {
"access_key": "",
"secret_key": ""
},
"placement_pools": [
{
"key": "zone1-placement",
"val": {
"index_pool": "class_hdd_pool_1.index",
"data_extra_pool": "class_hdd_pool_1.non-ec",
"storage-classes": {
"STANDARD": {
"data_pool": "class_hdd_pool_1.data"
},
"CLOD": {
"data_pool": "class_hdd_pool_2.data"
}
},
"index_type": 0,
"compression": "",
}
}
],
"metadata_heap": "",
"tier_config": [],
"realm_id": ""
}
问题:zon1文件中虽然指定了storage-classes.STANDARD.data_pool:class_hdd_pool_1.data, 但使用命令 radosgw-admin zone get –rgw-zone=zone1 查看时候并不会显示出 data_pool的指定pool, 这一点原因不清楚。
[root@ceph-3 storage-class]# radosgw-admin zone get
{
"id": "6d8016ed-1e4d-4a65-9106-243f3a318d06",
"name": "zone1",
.....
"placement_pools": [
{
"key": "zone1-placement",
"val": {
"index_pool": "class_hdd_pool_1.index",
"storage_classes": {
"STANDARD": { // 这里并不显示data_pool
"compression_type": ""
}
},
"data_extra_pool": "class_hdd_pool_1.non-ec",
"index_type": 0
}
}
],
....
}
由于radosgw-admin zone get –rgw-zone=zone1查看不显示data_pool,因此这里再显式的更改一下:
[root@ceph-3 storage-class]# radosgw-admin zonegroup placement add --rgw-zonegroup=petreloss --placement-id=zone1-placement
[root@ceph-3 storage-class]# radosgw-admin zone placement modify --rgw-zone=zone1 --data-pool=class_hdd_pool_1.data --placement-id=zone1-placement \
--data-pool=class_hdd_pool_1.data
问题:为什么一个 placement 必须先加入 zonegroup 后,才能再zone中添加?
- zone placement / zonegroup placement的关系是什么?
- zonegroup placement和zone placement之间的关键是:整个集合 与 子集的关系。
查看一下:
[root@ceph-3 storage-class]# radosgw-admin zone get --rgw-zone=zone1
{
"id": "6d8016ed-1e4d-4a65-9106-243f3a318d06",
"name": "zone1",
....
"placement_pools": [
{
"key": "zone1-placement",
"val": {
"index_pool": "class_hdd_pool_1.index",
"storage_classes": {
"STANDARD": {
"data_pool": "class_hdd_pool_1.data", //已经存在
"compression_type": ""
}
},
"data_extra_pool": "class_hdd_pool_1.non-ec",
"index_type": 0
}
}
],
....
}
此时我们已经将使用class_hdd_pool_1.xxx的placement创建完了。
4.2 在zone1-placement中添加CLOD
#get zg
radosgw-admin zonegroup get --rgw-zonegroup=petreloss > zonegroup.json
vim zonegroup.json
在storage_classes中添加"CLOD":
{
...
"placement_targets": [
{
"name": "zone1-placement",
"tags": [],
"storage_classes": [
"CLOD",
"STANDARD"
]
}
],
...
}
#set
radosgw-admin zonegroup set --rgw-zonegroup=petreloss --infile=zonegroup.json
#get zone
radosgw-admin zone get --rgw-zone=zone1 > zone.json
vim zone.json
在storage_classes中添加"CLOD"相关信息:
{
......
"placement_pools": [
{
"key": "zone1-placement",
"val": {
"index_pool": "class_hdd_pool_1.index",
"storage_classes": {
"CLOD": {
"data_pool": "class_hdd_pool_2.data"
},
"STANDARD": {
"data_pool": "class_hdd_pool_1.data",
"compression_type": ""
}
},
"data_extra_pool": "class_hdd_pool_1.non-ec",
"index_type": 0
}
}
],
......
}
#set
radosgw-admin zone set --rgw-zone=zone1 --infile=zone.json
查看一下:
"placement_pools": [
{
"key": "zone1-placement",
"val": {
"index_pool": "class_hdd_pool_1.index",
"storage_classes": {
"CLOD": {
"data_pool": "class_hdd_pool_2.data"
},
"STANDARD": {
"data_pool": "class_hdd_pool_1.data",
"compression_type": ""
}
},
"data_extra_pool": "class_hdd_pool_1.non-ec",
"index_type": 0
}
}
],
至此,4步骤做完。
5. 创建user, bucket
5.1 创建user
radosgw-admin user create --uid="user123" --display-name="user123"
- 问题: 创建用户时候如果不指定 –placement-id 字段,则该用户将会使用zonegroup中默认的placement作为placement target. 这时候如果zg中的default-placement被删除,那么再创建user时候并不会报错,但是在使用该用户创建bucket时候会报错:ERROR: S3 error: 400 (InvalidLocationConstraint)。查看rgw日志,发现在zonegroup中找不到 default-placement。
- 解决办法:创建用户时候指定 –placement-id字段,如:–placement-id=zone1-placement.
上述解决方法是官方给的,我测试下貌似不管用:
[root@ceph-3 s3cmd]# radosgw-admin user modify --uid=user123 --placement-id=zone1-placement
{
"user_id": "user123",
"display_name": "user123",
...
"default_placement": "", //并未填充进去
...
}
改进方法:
radosgw-admin metadata get user:user123 > user.md.json
vim user.md.json //将default_placement字段填上保存退出即可
radosgw-admin metadata put user:user123 < user.md.json
再次查看default_placement就有了。
- 问题: 如果你使用了含有default-placement的user创建了bucket:bucket-01, 但是由于种种原因, 你删掉了default-placement,并重新为user指定默认的placement,比如上边所属的:zone1-placement。那么bucket-01之后既不能进行上传文件,也不能被删除,因为系统会去查找之前与该user对应的默认placement,结果找不到,就会报错:ERROR: S3 error: 400 (InvalidArgument)。
查看rgw日志,显示:
NOTICE: invalid dest placement: default-placement
init_permissions on sensebucket[83166252-1bf5-43e2-80f7-bd3e40c0edf3.96363.1] failed, ret=-22
5.2 创建bucket
使用s3cmd进行bucket创建:
s3cmd mb s3://sensebucket
6. 修改policy
使用python中的 boto3 sdk 进行lifecycle的操作:
- 安装 boto3
pip install boto3
- 修改rgw的配置文件
vim /etc/ceph/ceph.conf
在rgw部分添加:
rgw_lifecycle_work_time = "00:00-24:00"
rgw_lc_debug_interval = -10
lifecycle 相关参数:
- rgw_lifecycle_work_time = “00:00-6:00” //执行lc时间窗口
- rgw_enable_lc_threads = true //允许启动lc线程,设置false表示关闭lc功能
- rgw_lc_lock_max_time = 60 //某个lc线程每次可以执行的总时间,超过该时间没执行完,就等下次执行
- rgw_lc_max_objs = 32 //lc rados对象个数
- rgw_lc_max_rules = 1000 //一个bucket可以设置的rule数
- rgw_lc_debug_interval = -10 //该配置主要为了方便调试lc。这个参数很关键,>0时,会忽略设置的时间窗口去执行,立即执行,并且此时设置的过期天数,1天等于1s,也就是说你设置7天后过期,此时表示7s后过期。<=0时,则按照正常的来执行。
- 重启rgw
- 编写 boto3的修改lifecycle的文件rgw_lifecycle_setup.py:
#!/usr/bin/env python2.7
#-*- coding: utf-8 -*-
import boto3
from botocore.client import Config
import datetime
if __name__ == "__main__":
endpoint = "http://192.168.2.27:80" #替换成你自己的endpoint
access_key = "HWY7QPBEBBEJB238T465" #替换
secret_key = "VMy2BV0SHSnNZtuDrwPRrtK3DffCZ9IOBUPdVh42" #替换
bucket = "sensebucket" #替换
s3 = boto3.client('s3',
endpoint_url=endpoint,
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
)
s3.put_bucket_lifecycle(
Bucket=bucket,
LifecycleConfiguration={
'Rules': [
{
'Status': 'Enabled',
'Prefix': '',
'Expiration':
{
'Days': 1
},
'ID': 'Unique_identifier_for_the_rule' #任何唯一的可作为ID的字符串即可
}
],
}
)
print s3.get_bucket_lifecycle(Bucket=bucket)
- 运行 ./rgw_lifecycle_setup.py
{u'Rules': [{u'Status': 'Enabled', u'Prefix': '', u'Expiration': {u'Days': 1}, u'ID': 'Unique_identifier_for_the_rule'}], 'ResponseMetadata': {'HTTPStatusCode': 200, 'RetryAttempts': 0, 'HostId': '', 'RequestId': 'tx000000000000000000014-005f645282-1798e-zone1', 'HTTPHeaders': {'date': 'Fri, 18 Sep 2020 06:24:02 GMT', 'content-length': '267', 'x-amz-request-id': 'tx000000000000000000014-005f645282-1798e-zone1', 'content-type': 'application/xml', 'connection': 'Keep-Alive'}}}
- 查看下:radosgw-admin lc list
[root@ceph-3 s3cmd]# radosgw-admin lc list
[
{
"bucket": ":sensebucket:83166252-1bf5-43e2-80f7-bd3e40c0edf3.96363.2",
"status": "COMPLETE"
}
]
等待一天后看看是否该bucket的文件被删除了。(目前ceph不支持lifecycle的transition,后续实现并补充一篇文章,到时候再来完善本文章。)
- 记录下本bucket下的文件:
[root@ceph-3 s3cmd]# s3cmd --recursive ls s3://sensebucket/
2020-09-18 06:08 5242880 s3://sensebucket/lifecycle_5MB.gz
2020-09-18 05:48 1233 s3://sensebucket/user.md.json
7. 验证生效
7.1 lifecycle的过期删除验证:
- 首先查一下结果看是否删掉:
[root@ceph-3 s3cmd]# s3cmd --recursive ls s3://sensebucket/
[root@ceph-3 s3cmd] //空
可见sensebucket中的文件已经被删除。
- 通过查询pool中的信息来从另一个角度证明该bucket的文件被删除
# 首先需要得到该bucket的id
[root@ceph-3 ~]# radosgw-admin bucket stats --bucket=sensebucket
{
"bucket": "sensebucket",
"num_shards": 0,
"tenant": "",
"zonegroup": "dc2a72aa-5db5-417c-9af0-1a8b6428d06a",
......
"id": "83166252-1bf5-43e2-80f7-bd3e40c0edf3.96363.1",
"marker": "83166252-1bf5-43e2-80f7-bd3e40c0edf3.96363.1",
"owner": "user123",
.......
}
# 去索引池查找该bucket id对应的信息
[root@ceph-3 ~]# rados -p class_hdd_pool_1.index ls - |grep 83166252-1bf5-43e2-80f7-bd3e40c0edf3.96363.1
.dir.83166252-1bf5-43e2-80f7-bd3e40c0edf3.96363.1
# 使用listomapkeys 过滤
[root@ceph-3 ~]# rados -p class_hdd_pool_1.index listomapkeys .dir.83166252-1bf5-43e2-80f7-bd3e40c0edf3.96363.1
[root@ceph-3 ~]# //空
# 直接查看data pool
[root@ceph-3 ~]# rados -p class_hdd_pool_1.data ls
[root@ceph-3 ~]# //空
8 lifecycle 之 transition
rgw lc中的transition是作用范围是:同一个placement下的storageclass之间。 由于之前标题4已经将zonegroup, zone上添加了 CLOD 的相关信息以及rgw的配置文件也添加了对应的lifecycle的配置。所以这里不需要做这方面操作。
8.1 boto3 lifecycle配置
LifecycleConfiguration={
'Rules': [
{
'Status': 'Enabled',
'Prefix': 'transclod-',
'Transition':
{
'Days': 1,
'StorageClass': 'CLOD'
},
'ID': 'sensebucket_id_0987654321' #uuid
}
],
}
执行该脚本,response:
{u'Rules': [{u'Status': 'Enabled', u'Prefix': 'transclod-', u'Transition': {u'Days': 1, u'StorageClass': 'CLOD'}, u'ID': 'sensebucket_id_0987654321'}], 'ResponseMetadata': {'HTTPStatusCode': 200, 'RetryAttempts': 0, 'HostId': '', 'RequestId': 'tx000000000000000000007-005f8031b2-176db-zone1', 'HTTPHeaders': {'date': 'Fri, 19 Sep 2020 09:47:30 GMT', 'content-length': '305', 'x-amz-request-id': 'tx000000000000000000007-005f8031b2-176db-zone1', 'content-type': 'application/xml', 'connection': 'Keep-Alive'}}}
8.2 测试
注意上边的Rules,Prefix是”transclod-“
我先上传一个不含有前缀的文件:
[root@ceph-3 ~]# s3cmd put test.5M.gz s3://sensebucket/test.5M.gz.clod.1009
upload: 'test.5M.gz' -> 's3://sensebucket/test.5M.gz.clod.1009' [1 of 1]
5242880 of 5242880 100% in 0s 19.43 MB/s done
分别查看 class_hdd_pool_1.data 和 class_hdd_pool_2.data, 发现 test.5M.gz.clod.1009 并没有被进行 transition。
[root@ceph-3 storage-class]# rados -p class_hdd_pool_1.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.sPQ50HnGJ3iXld7Dpvor7lDKsdlpbjH_1
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_test.5M.gz.clod.1009
[root@ceph-3 storage-class]#
[root@ceph-3 storage-class]# rados -p class_hdd_pool_2.data ls
[root@ceph-3 storage-class]#
在上传一个小于4MB的文件, 含有前缀 ‘transclod-‘:
[root@ceph-3 s3cmd]# s3cmd put user.md.json s3://sensebucket/transclod-user.md.json.1009
upload: 'user.md.json' -> 's3://sensebucket/transclod-user.md.json.1009' [1 of 1]
1233 of 1233 100% in 0s 21.40 KB/s done
分别查看 class_hdd_pool_1.data 和 class_hdd_pool_2.data:
[root@ceph-3 storage-class]# rados -p class_hdd_pool_1.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-user.md.json.1009 #执行了transition
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.sPQ50HnGJ3iXld7Dpvor7lDKsdlpbjH_1
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_test.5M.gz.clod.1009
[root@ceph-3 storage-class]#
[root@ceph-3 storage-class]# rados -p class_hdd_pool_2.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.vgXJ_TO-bsHFcqVWG8p6mvtc_ykVv-w_0
[root@ceph-3 storage-class]#
同样做了大于4MB的测试, 结果是也会执行 transition.
执行了lifecycle之后, 为什么 class_hdd_pool_1.data 中依然有对象数据呢?我们查看下这些对象的stat
rados -p class_hdd_pool_1.data stat 8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-user.md.json.1009
class_hdd_pool_1.data/8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-user.md.json.1009 mtime 2020-10-09 05:50:02.000000, size 0
发现执行 transition的对象 size=0. 现在将该文件 transclod-user.md.json.1009 的stat 整个读取出来分析下:
radosgw-admin object stat --bucket=sensebucket --object=transclod-user.md.json.1009 > transclod-user.info
transclod-user.info文件内容如下:
{
"name": "transclod-user.md.json.1009",
"size": 1233,
"policy": {
"acl": {
.....
},
"owner": {
"id": "1009-user-01",
"display_name": "1009-user-01"
}
},
"etag": "d29d1ce22651886745d53560ffa097cb",
"tag": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95963.9",
"manifest": {
"objs": [],
"obj_size": 1233,
"explicit_objs": "false",
"head_size": 0,
"max_head_size": 0,
"prefix": ".vgXJ_TO-bsHFcqVWG8p6mvtc_ykVv-w_",
"rules": [
{
"key": 0,
"val": {
"start_part_num": 0,
"start_ofs": 0,
"part_size": 0,
"stripe_max_size": 4194304,
"override_prefix": ""
}
}
],
"tail_instance": "",
"tail_placement": {
"bucket": {
"name": "sensebucket",
"marker": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1",
"bucket_id": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1",
"tenant": "",
"explicit_placement": {
"data_pool": "",
"data_extra_pool": "",
"index_pool": ""
}
},
"placement_rule": "zone1-placement/CLOD"
},
"begin_iter": { #begin_iter 和 end_iter 完全一样, 并且 {manifest.obj_size} == 1233 < 4MB, 故只有一个分片
"part_ofs": 0,
"stripe_ofs": 0,
"ofs": 0,
"stripe_size": 1233,
"cur_part_id": 0,
"cur_stripe": 0,
"cur_override_prefix": "",
"location": {
"placement_rule": "zone1-placement/CLOD", #当前分片存的存放规则
"obj": {
"bucket": {
"name": "sensebucket",
"marker": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1",
"bucket_id": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1",
"tenant": "",
"explicit_placement": {
"data_pool": "",
"data_extra_pool": "",
"index_pool": ""
}
},
"key": {
"name": ".vgXJ_TO-bsHFcqVWG8p6mvtc_ykVv-w_0", # ${marker}_${begin_iter.location.obj.key.name} 即为首分片名
"instance": "",
"ns": "shadow"
}
},
"raw_obj": {
"pool": "",
"oid": "",
"loc": ""
},
"is_raw": false
}
},
"end_iter": {
"part_ofs": 0,
"stripe_ofs": 0,
"ofs": 1233,
"stripe_size": 1233,
"cur_part_id": 0,
"cur_stripe": 0,
"cur_override_prefix": "",
"location": {
"placement_rule": "zone1-placement/CLOD",
"obj": {
"bucket": {
"name": "sensebucket",
"marker": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1",
"bucket_id": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1",
"tenant": "",
"explicit_placement": {
"data_pool": "",
"data_extra_pool": "",
"index_pool": ""
}
},
"key": {
"name": ".vgXJ_TO-bsHFcqVWG8p6mvtc_ykVv-w_0",
"instance": "",
"ns": "shadow"
}
},
"raw_obj": {
"pool": "",
"oid": "",
"loc": ""
},
"is_raw": false
}
}
},
"attrs": {
"user.rgw.content_type": "text/plain",
"user.rgw.pg_ver": "",
"user.rgw.source_zone": "`<80>n$",
"user.rgw.storage_class": "CLOD",
"user.rgw.tail_tag": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95963.9",
"user.rgw.x-amz-content-sha256": "eace10acc865aedde72fc44a1cdcef24bb6203a149a1d6db268651ddfb930e35",
"user.rgw.x-amz-date": "20201009T095002Z",
"user.rgw.x-amz-meta-s3cmd-attrs": "atime:1602230611/ctime:1600398602/gid:0/gname:root/md5:d29d1ce22651886745d53560ffa097cb/mode:33188/mtime:1600398602/uid:0/uname:root"
}
}
9 另一种 transition 解析
上述的 transition 是从 默认的storage_class=STANDARD 转移到storage_class=CLOD的,对象的header数据存放在STANDARD所在的pool中, 这里的data size=0, 数据信息被转移到 CLOD所在的pool中。
本实验是将数据直接上传至 CLOD中, 然后制定lc策略, 将数据转移到 STANDARD中, 然后分析下结果。
1>. 先看下现有的池子中的数据情况:
[root@ceph-3 ~]# rados -p class_hdd_pool_1.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-user.md.json.1009
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-5mb.1009
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-test.1009
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.sPQ50HnGJ3iXld7Dpvor7lDKsdlpbjH_1
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_test.5M.gz.clod.1009
[root@ceph-3 ~]# rados -p class_hdd_pool_2.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.vgXJ_TO-bsHFcqVWG8p6mvtc_ykVv-w_0
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.6LI53GKdlVrAd_bv8wvPBmv9OyYzbZg_0
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.cE4sjjs_HPFC4d19llRRYkz-mBhN2V1_1
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.cE4sjjs_HPFC4d19llRRYkz-mBhN2V1_0
2>. 使用s3cmd上传一个新文件到 CLOD中:
[root@ceph-3 ~]# s3cmd put zone1.bak s3://bucket2/uptransfer-zone1.bak.1015 --storage-class=CLOD
upload: 'zone1.bak' -> 's3://bucket2/uptransfer-zone1.bak.1015' [1 of 1]
1846 of 1846 100% in 0s 55.20 KB/s done
3>. 查看数据池中的情况:
[root@ceph-3 ~]# rados -p class_hdd_pool_1.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-user.md.json.1009
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-5mb.1009
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_transclod-test.1009
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2_uptransfer-zone1.bak.1015 // 新上传的文件, size = 0
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.sPQ50HnGJ3iXld7Dpvor7lDKsdlpbjH_1
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1_test.5M.gz.clod.1009
[root@ceph-3 ~]#
rados -p class_hdd_pool_1.data stat 8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2_uptransfer-zone1.bak.1015
class_hdd_pool_1.data/8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2_uptransfer-zone1.bak.1015 mtime 2020-10-14 22:53:56.000000, size 0
[root@ceph-3 ~]# rados -p class_hdd_pool_2.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.vgXJ_TO-bsHFcqVWG8p6mvtc_ykVv-w_0
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.6LI53GKdlVrAd_bv8wvPBmv9OyYzbZg_0
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2__shadow_.xlPy_gdmzIsI2C9nwhZCM9d9suP4mnf_0 //uptransfer-zone1.bak.1015
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.cE4sjjs_HPFC4d19llRRYkz-mBhN2V1_1
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.cE4sjjs_HPFC4d19llRRYkz-mBhN2V1_0
4>. 为该bucket制定 lc 策略:
'Rules': [
{
'Status': 'Enabled',
'Prefix': 'uptransfer-',
'Transition':
{
'Days': 1,
'StorageClass': 'STANDARD'
},
'ID': 'transbucket_id_0987654321_uptransfer_bucket2'
}
]
5>. 执行lc策略脚本:
[root@ceph-3 uplayer_transition]# ./rgw_lifecycle_setup.py
{u'Rules': [{u'Status': 'Enabled', u'Prefix': 'uptransfer-', u'Transition': {u'Days': 1, u'StorageClass': 'STANDARD'}, u'ID': 'transbucket_id_0987654321_uptransfer_bucket2'}], 'ResponseMetadata': {'HTTPStatusCode': 200, 'RetryAttempts': 0, 'HostId': '', 'RequestId': 'tx000000000000000000020-005f87bafe-176db-zone1', 'HTTPHeaders': {'date': 'Thu, 15 Oct 2020 02:59:10 GMT', 'content-length': '329', 'x-amz-request-id': 'tx000000000000000000020-005f87bafe-176db-zone1', 'content-type': 'application/xml', 'connection': 'Keep-Alive'}}}
6>. 查看两个数据池是否发生变化
[root@ceph-3 ~]# rados -p class_hdd_pool_1.data stat 8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2_uptransfer-zone1.bak.1015
class_hdd_pool_1.data/8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2_uptransfer-zone1.bak.1015 mtime 2020-10-14 22:53:56.000000, size 1846
//此时data2中的数据依然存在
[root@ceph-3 ~]# rados -p class_hdd_pool_2.data stat 8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2__shadow_.xlPy_gdmzIsI2C9nwhZCM9d9suP4mnf_0
class_hdd_pool_2.data/8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2__shadow_.xlPy_gdmzIsI2C9nwhZCM9d9suP4mnf_0 mtime 2020-10-14 22:53:56.000000, size 1846
可以看到, 数据已经转移到 STANDARD 上了.
7>. CLOD上的数据会不会被删除?
查看gc 列表:
//查看gc任务:
[root@ceph-3 ~]# radosgw-admin gc list
[
{
"tag": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95963.30\u0000",
"time": "2020-10-15 00:59:32.0.926761s",
"objs": [
{
"pool": "class_hdd_pool_2.data",
"oid": "8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2__shadow_.xlPy_gdmzIsI2C9nwhZCM9d9suP4mnf_0", //待删除的gc_oid
"key": "",
"instance": ""
}
]
}
]
发现, pool_2中的该对象已经被添加进了gc列表, 意思就是该对象会被异步删除掉。
8>. 查看rgw_gc参数:
//查看rgw_gc参数
ceph --admin-daemon ceph-client.rgw.ceph-2.rgw0.28965.93983884214936.asok config show|grep gc
"rgw_gc_max_concurrent_io": "10",
"rgw_gc_max_objs": "32", //gc hint obj个数
"rgw_gc_max_trim_chunk": "16",
"rgw_gc_obj_min_wait": "7200", //对象被gc回收前最少等待时间:2小时
"rgw_gc_processor_max_time": "3600", //gc hint obj的超时时间
"rgw_gc_processor_period": "3600", //gc线程运行周期
"rgw_nfs_max_gc": "300",
"rgw_objexp_gc_interval": "600",
等两小时在看下gc list 以及 pool_2的数据显示。
9>. 经过2小时后,查看gc list以及 pool_2数据显示.
[root@ceph-3 ~]# radosgw-admin gc list //空了
[]
[root@ceph-3 ~]# rados -p class_hdd_pool_1.data stat 8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2_uptransfer-zone1.bak.1015
class_hdd_pool_1.data/8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.2_uptransfer-zone1.bak.1015 mtime 2020-10-14 22:53:56.000000, size 1846
[root@ceph-3 ~]# rados -p class_hdd_pool_2.data ls
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.vgXJ_TO-bsHFcqVWG8p6mvtc_ykVv-w_0
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.6LI53GKdlVrAd_bv8wvPBmv9OyYzbZg_0
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.cE4sjjs_HPFC4d19llRRYkz-mBhN2V1_1
8fb2def7-7ccd-4803-a76a-566554e21b9e.95969.1__shadow_.cE4sjjs_HPFC4d19llRRYkz-mBhN2V1_0
可以看到 gc list 已经为空。 pool_2中的数据:shadow.xlPy_gdmzIsI2C9nwhZCM9d9suP4mnf_0 已经被删除。 至此,数据由 CLOD 彻底的转移到了 STANDARD 中。
