pagecache
-
在我们进行数据持久化, 对文件内容进行落盘处理时, 我们时常会使用fsync操作, 该操作会将文件关联的脏页(dirty page)数据(实际文件内容及元数据信息)一同写回磁盘. 这里提到的脏页(dirty page)即为页缓存(page cache).
-
块缓存(buffer cache), 则是内核为了加速对底层存储介质的访问速度, 而构建的一层缓存. 他缓存部分磁盘数据, 当有磁盘读取请求时, 会首先查看块缓存中是否有对应的数据, 如果有的话, 则直接将对应数据返回, 从而减少对磁盘的访问.
page cache
page cache以page为单位, 缓存文件内容. 缓存在page cache中的文件数据能够更快的被用户读取. 同时对于带buffer的写入操作或者非 O_DIRECT 写入操作, 数据在写入到page cache中后会立即返回, 而不需要等待数据实际被持久化到磁盘, 进而提高了上层应用读写文件的整体性能.
buffer cache
磁盘的最小数据单位是 sector, 每次读写磁盘都是以 sector为单位进行磁盘操作. sector大小根具体的磁盘类型有关, 目前大多数sata盘的sector大小为521Byte, 当然也有4kByte的. 无论用户希望读取 1byte还是10byte, 最终访问磁盘时, 都必须以sector为单位读取. 同样的, 如果用户想在磁盘的某个位置写入(更新)1byte数据, 那么他也必须刷新整个sector, 言外之意是:用户希望写入(更新)这 1byte数据, 首先要做的是将这个sector读出来, 在内存中修改之后再将这一整个sector写入磁盘. 为了降低这种低效的访问, 尽可能的提升磁盘访问性能, 内核会在磁盘sector上构建一层缓存, 它以sector的整数倍为单位(block), 缓存部分sector数据在内存中的, 当有数据读取请求时, 它能够直接从内存中将对应的数据读出. 当有数据写入时, 它可以直接在内存中更新指定部分的数据, 然后通过异步的方式把更新后的数据写回对应的磁盘的sector中. 这层缓存就是块缓存 buffer cache.
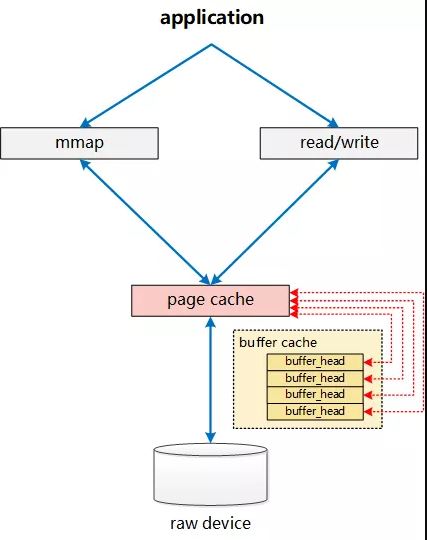
两类缓存的逻辑关系
从 linux-2.6.18内核源码上分析,page cache和buffer cache是一个组件的两种表现形式: 对于page而言(对上), 它是某个file的一个page cache, 对下它是一个device上的一组buffer cache.
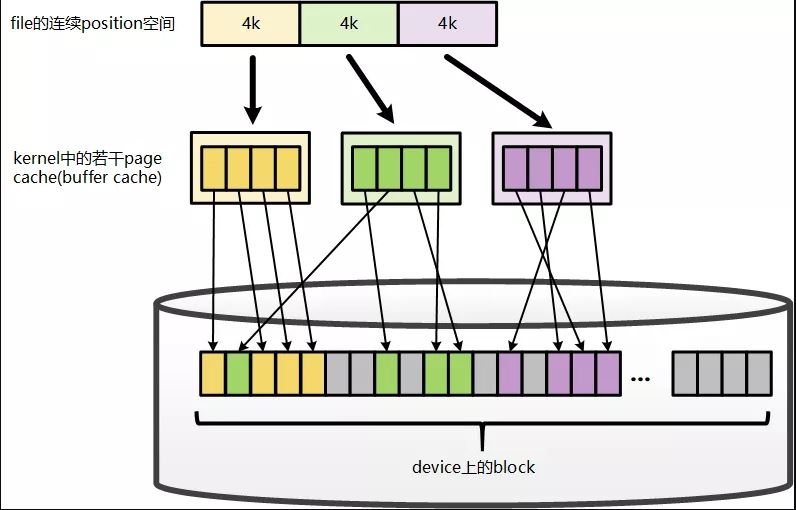
一个file如果是全部(部分)放在内存中,则存放在内存中的部分是以 4K(page size)为单位进行切分的, 而这一个page指的就是一个page cache. 而对应于落盘的一个文件而言, 最终这个4k的page cache还要映射到一组磁盘的block对应的buffer cache上, 假设block为1k, 那么每个pagecache将对应一组(4个)buffer cache, 而每一个buffer cache则有一个对应的buffer cache与device block映射关系的描述符: buffer_head, 这个描述符记录了这个buffer cache对应的磁盘上的具体位置.
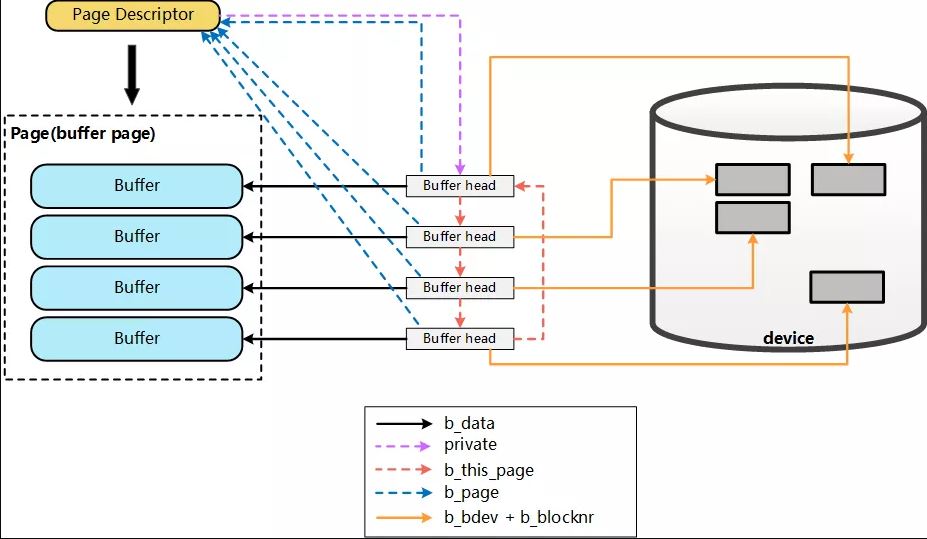
上图只展示了page cache与buffer cache以及对应的block之间的关联关系. 而从file的角度来看,想将数据写入磁盘,第一步则是需要找到file具体对应的page cache的哪个page? 进而才能将数据写入, 而要找到对应的page, 则依赖于inode结构中的 i_mapping字段:

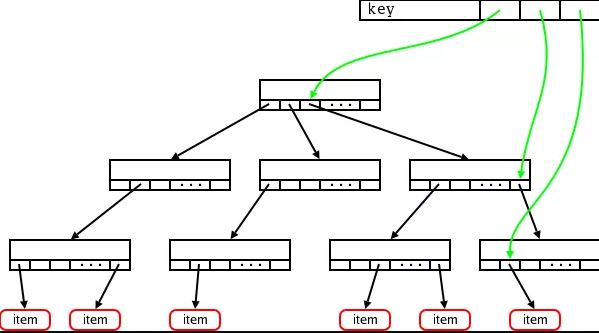
该字段为一 address_space 结构, 而实际上 address_space 即为一棵radix tree. 简单来说, radix tree即为一个多级索引结构, 如果将一个文件的大小, 以page为单位来切分,假设一个文件有N个page, 这个N是一个32bit的int, 那么, 这个32bit的N, 可以被切分成若干层级:level-0: [0 - 7bit], level-1:[8 - 15bit], level-2: [16 - 23bit], level-3: [24 - 31bit]. 在查找File某个位置对应的page是否存在时, 则拿着这个page所在的位置N, 到对应的radix-tree上查找. 查找时, 首先通过N中的level-0部分, 到radix tree上的level-0层级索引上去查找, 如果不存在, 则直接告知不存在, 如果存在, 则进一步的, 拿着N中的level-1部分, 到这个level-0下面对应的level-1去查找, 一级一级查找. 这样, 我们可以看出, 最多, 在4层索引上查找, 就能找到N对应的page信息.
radix-tree及address_space的详细描述:
- Trees I: Radix trees
- Professional Linux Kernel Architecture
基本的radix-tree映射结构:
对应的inode上, i_mapping字段(address_space)对page的映射关系:
融合
linux-2.4之后page cache和buffer cache的实现进行了融合, 融合之后buffer cache的内容直接存在于page cache中:
page结构中, 通过 buffers 字段是否为空, 来判定这个Page是否与一组Buffer Cache关联:
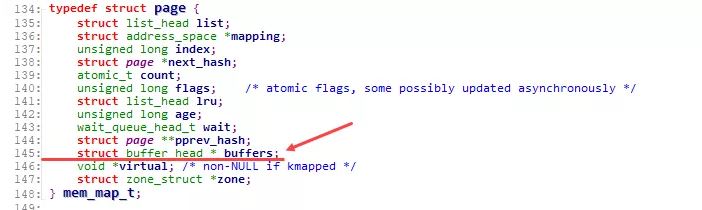 一个page中buffers字段指向一个buffer_head链表, 每个buffer_head都对应一个buffer
一个page中buffers字段指向一个buffer_head链表, 每个buffer_head都对应一个buffer
而对应的, buffer_head则增加了字段 b_page , 直接指向对应的page:
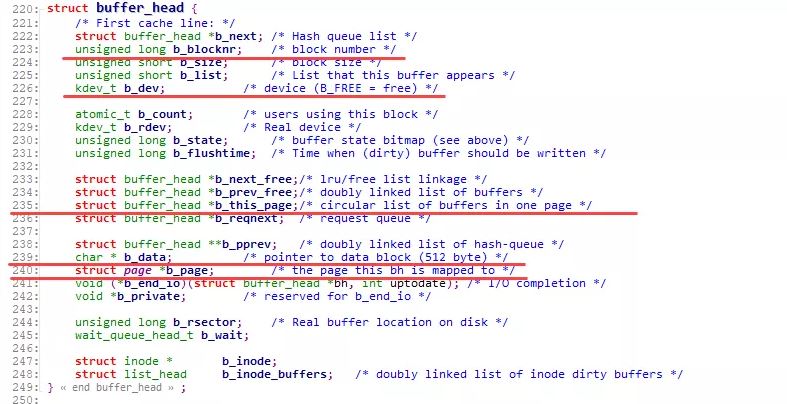
至此, 两者的关系已经相互融合如下图所示:

一个文件的PageCache(page), 通过 buffers 字段能够非常快捷的确定该page对应的buffer_head信息, 进而明确该page对应的device, block等信息.
从逻辑上来看, 当针对一个文件的write请求进入内核时, 会执行 generic_file_write , 在这一层, 通过inode的address_space结构 mapping 会分配一个新的page来作为对应写入的page cache(这里我们假设是一个新的写入, 且数据量仅一个page):grab_cache_page , 而在分配了内存空间page之后, 则通过 prepare_write , 来完成对应的buffer_head的构建.
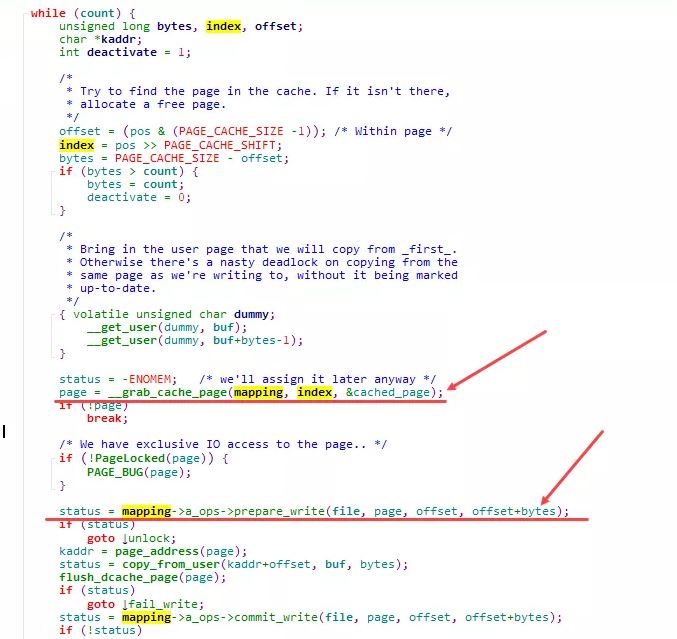
prepare_write 实际执行的是:block_prepare_write , 在其中, 会针对该page分配对应的buffer_head( create_empty_buffers ), 并计算实际写入的在device上的具体位置:blocknr, 进而初始化buffer_head( get_block )
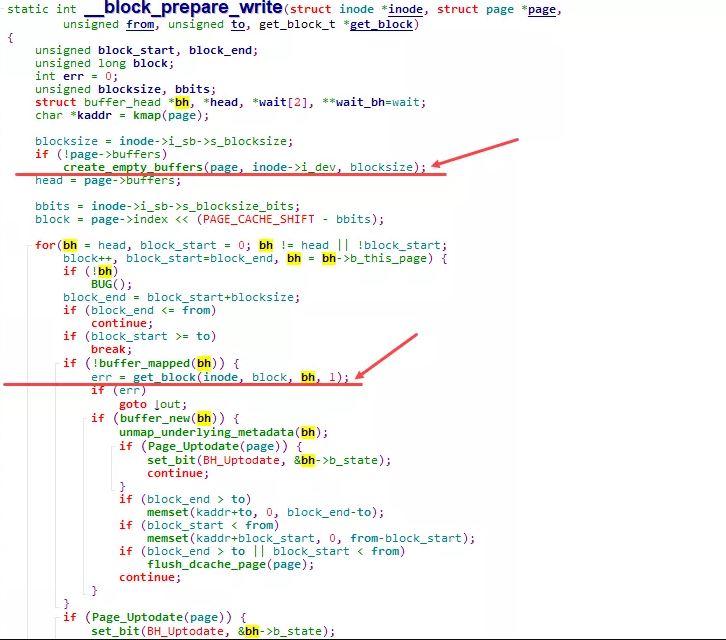
在 create_empty_buffers 内部, 则通过 create_buffers 以及 set_bh_page 等一系列操作, 将page与buffer_head组织成如前图所示的通过 buffers 、 b_page 等相互关联的关系.
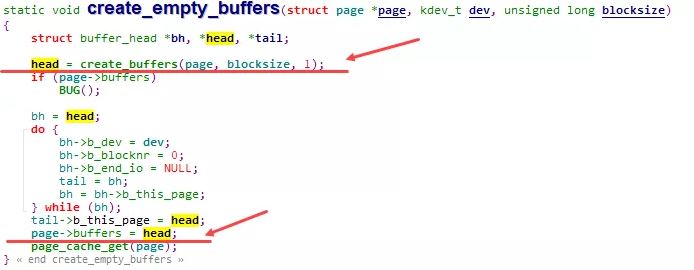
通过 create_buffers 分配一组串联好的buffer_head:
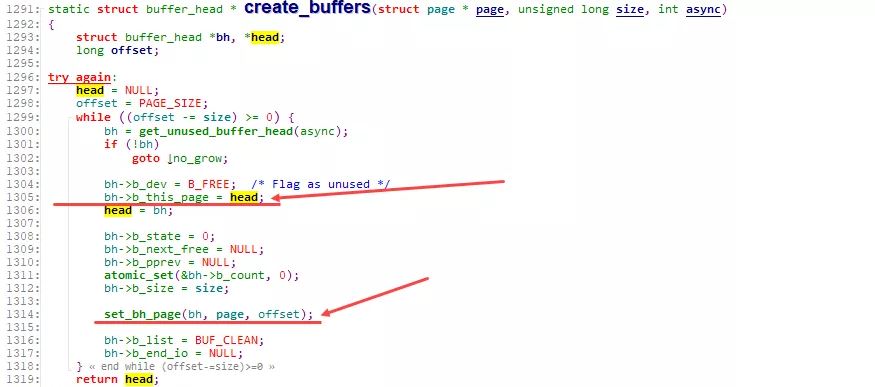
通过 set_bh_page 将各buffer_head关联到对应的page, 以及data的具体位置:
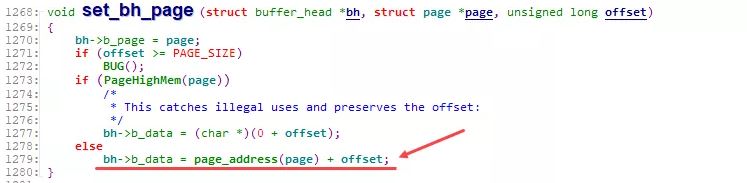
正是如上的一系列动作, 使得Page Cache与Buffer Cache(buffer_head)相互绑定. 对上, 在文件读写时, 以page为单位进行处理. 而对下, 在数据向device进行刷新时, 则可以以buffer_head(block)为单位进行处理.
在后续的linux-2.5版本中, 引入了bio结构来替换基于buffer_head的块设备IO操作.
这里的Page Cache与Buffer Cache的融合, 是针对文件这一层面的Page Cache与Buffer Cache的融合. 对于跨层的:File层面的Page Cache和裸设备Buffer Cache, 虽然都统一到了基于Page的实现, 但File的Page Cache和该文件对应的Block在裸设备层访问的Buffer Cache, 这两个是完全独立的Page, 这种情况下, 一个物理磁盘Block上的数据, 仍然对应了Linux内核中的两份Page, 一个是通过文件层访问的File的Page Cache(Page Cache), 一个是通过裸设备层访问的Page Cache(Buffer Cache).
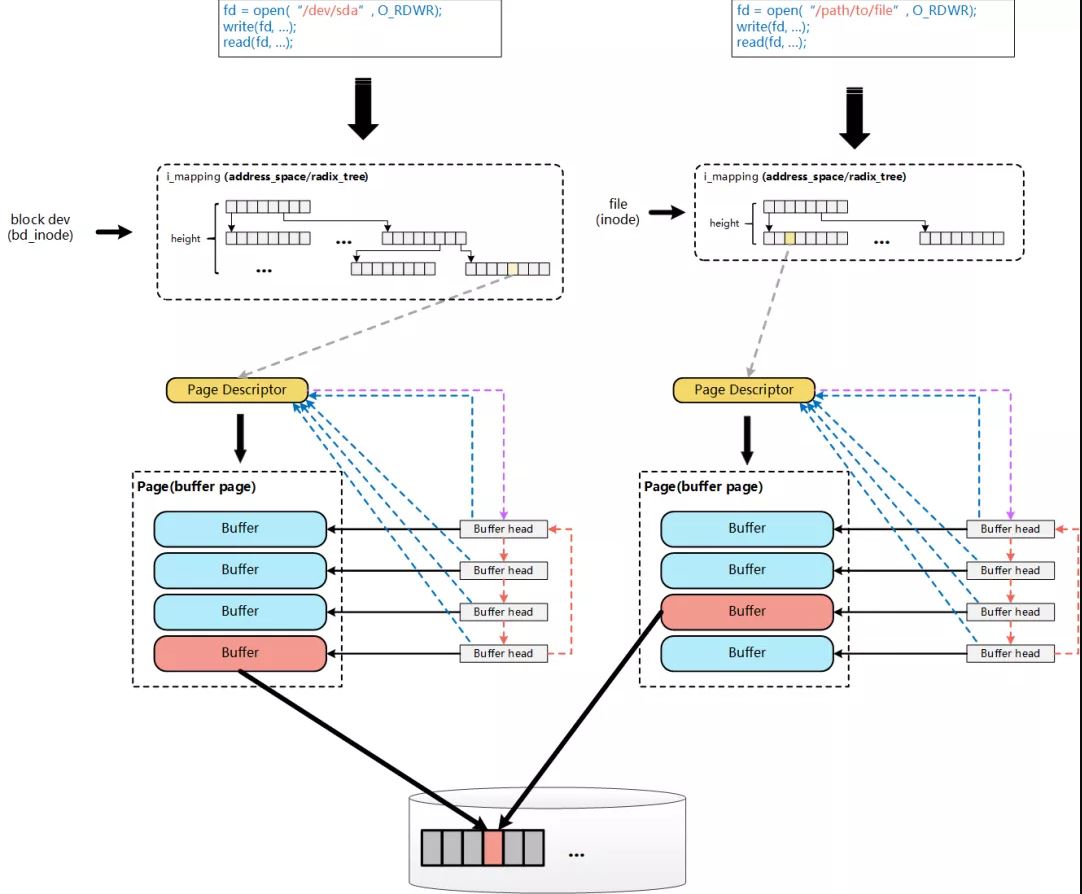
上图左边是通过open裸设备来进行page的访问, 上图右边是通过open file来进行page的访问. 虽然这两个访问使用到的page cache和buffer cache都是基于page来实现的(如图底层数据集中的一个红色page), 但在内核中该page却存在两份, 分别用于通过file访问的以及通过裸设备进行访问的.
