x86架构下的cache组织结构
在stackoverflow上看到一个非常有意思的问题: Why is transposing a matrix of 512×512 much slower than transposing a matrix of 513×513 ?
原文地址: https://stackoverflow.com/questions/11413855/why-is-transposing-a-matrix-of-512x512-much-slower-than-transposing-a-matrix-of
cache 的分级和耗时
cache是存在与cpu和main memory之间的高速缓存, 存在的意义是为了缓和cpu和memory之间的速度差距. 看一下cache和memory的访问时间:
- L1 cache: 0.5 ns
- L2 cache: 7 ns
- main memory: 100 ns
查看一下自己的服务器中1,2,3级cache的大小:
[root@HOST-xxx ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
型号名称: Intel(R) Xeon(R) Gold 6248R CPU @ 3.00GHz
CPU MHz: 3001.000
CPU max MHz: 3001.0000
CPU min MHz: 1200.0000
L1d 缓存: 32K //L1 data cache 数据cache
L1i 缓存: 32K //L1 instruct cache 指令cache
L2 缓存: 1024K
L3 缓存: 36608K
cache和memory的数据交换方式
cpu和memory是以字节为单位进行数据交换的, 而cache是以行为单位进行数据交换的,行:cache line。 在cache中划分若干个字为一行, 在内存中划分若干个字为一块,这里行和块的大小是相等的. cpu要获取某内存地址中的数据时会先检查该地址所在的块是否在cache中, 如果命中,cpu直接从cache中读取数据即可. 未命中则需要读内存并将该地址所在的整个内存块都复制到caheline 中.
全相联映射
这种映射方式很简单,内存中的任意一块都可以放置到cache中的任意一行去。为了便于说明,我们给出以下的简单模型来理解这个设计。 我们假设有一个4行的cache,每行4个字,每个字占4个字节,即64字节的容量。另外还有256字节(16块,每块4字,每字4字节)的一个RAM存储器来和这个cache进行映射。映射结构如图所示:
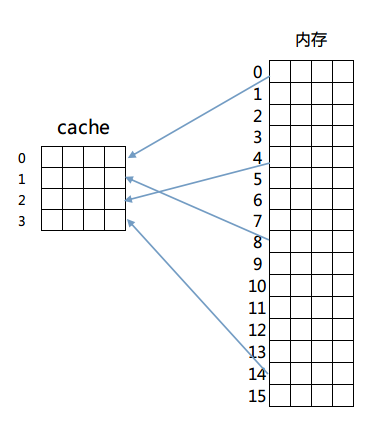
那么如何判断cache是否命中呢?由于内存和cache是多对一的映射,所以必须在cache存储一行数据的同时标示出这些数据在内存中的确切位置。简单的说,在cache每一行中都有一个Index,这个Index记录着该行数据来自内存的哪一块(其实还有若干标志位,包括有效位(valid bit)、脏位(dirty bit)、使用位(use bit)等。这些位在保证正确性、排除冲突、优化性能等方面起着重要作用)。那么在进行一个地址的判断时,采用全相联方式的话,因为任意一行都有可能存在所需数据,所以需要比较每一行的索引值才能确定cache中是否存在所需数据。这样的电路延迟较长,设计困难且复杂性高,所以一般只有在特殊场合,比如cache很小时才会使用。
直接相连映射
这个方法固定了行和块的对应关系,例如内存第0块必须放在cache第0行,第一块必须放在第一行,第二块必须放在第二行……循环放置,即满足公式:
内存块放置行号 = 内存块号 % cache总行数
映射如图所示:
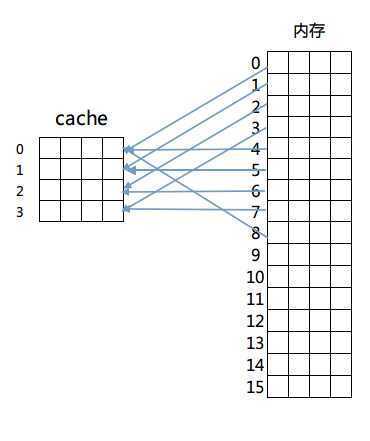
这样做解决了比较起来困难的问题,由于每一块固定到了某一行,只需要计算出目标内存所在的行号进行检查即可判断出cache是否命中。但是这么做的话因为一旦发生冲突就必须换出cache中的指定行,频繁的更换缓存内容造成了大量延迟,而且未能有效利用程序运行期所具有的时间局部性。
组相联映射
综上,最终的解决方案是最后的组相联映射方式(Set Associativity),这个方案结合了以上两种映射方式的优点。具体的方法是先将cache的行进行分组,然后内存块按照组号求模来决定该内存块放置到cache的哪一个组。但是具体放置在组内哪一行都可以,具体由cache替换算法决定。
我们依旧以上面的例子来说明,将cache里的4行分为两组,然后采用内存里的块号对组号求模的方式进行组号判断,即内存0号块第一组里,2号块放置在第二组里,3号块又放置在第一组,以此类推。这么做的话,在组内发生冲突的话,可以选择换出组内一个不经常读写的内存块,从而减少冲突,更好的利用了资源(具体的cache替换策略不在讨论范围内,有兴趣的童鞋请自行研究)。同时因为组内行数不会很多,也避免了电路延迟和设计的复杂性。
x86下的cache映射
x86中cache的组织方式采用的便是组相联映射方式。 我们刚说过组相联映射方式的行号可以通过 [ 块号 % 分组个数 ]的公式来计算, 那么直接给出一个内存地址的话如何计算呢? 其实内存地址所在的块号就是 [ 内存地址值 / 分块字节数 ], 那么直接由一个内存地址计算出所在cache中的行分组的组号计算公式就是:
内存地址所在cache组号 = (内存地址值 / 分块字节数) % 分组个数
假定一个cache行(内存块)有4个字,我们画出一个32位地址拆分后的样子:

因为字长32的话,每个字有4个字节,所以需要内存地址最低2位是字节偏移,同理每行(块)有4个字,块内偏移也是2位。这里的索引位数取决于cache里的行数,这个图里我画了8位,那就表示cache一共有256个分组(0~255)存在,每个分组有多少行呢?这个随意了,这里的行数是N,cache就是N路组相联映射。
具体的判断自然是取tag进行组内逐一匹配测试了,如果不幸没有命中,那就需要按照cache替换算法换出组内的一行了。顺带画出这个地址对应的cache结构图:
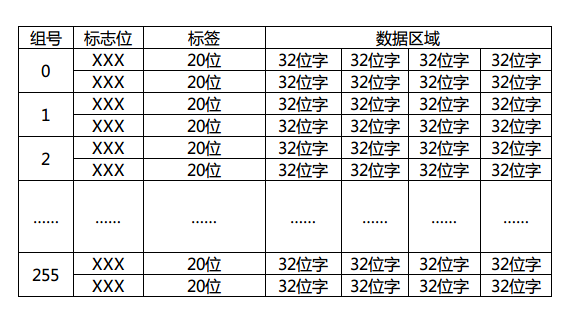
标志位是有效位(valid bit)、脏位(dirty bit)、使用位(use bit)等,用于该cache行的写回算法,替换算法使用。这里简单期间我就画了一个2路组相联映射的例子出来。现在大家应该大致明白cache工作的流程了吧?首先由给出的内存地址计算出所在cache的组号(索引),再由判断电路逐一比较标签(tag)值来判断是否命中,若命中则通过行(块)内偏移返回所在字数据,否则由cache替换算法决定换出某一行(块),同时由内存调出该行(块)数据进行替换。
512 && 513问题
512×512的矩阵,或者用C语言的说法称之为512×512的整型二维数组,在内存中是按顺序存储的。 那么以我的机器为例,在上面的lscpu命令输出的结果中,L1d(一级数据缓存)拥有32KB的容量。但是,有没有更详细的行大小和分组数量的信息?当然有,而且不需要多余的命令。在/sys/devices/system/cpu目录下就可以看到各个CPU核的所有详细信息,当然也包括cache的详细信息,我们主要关注L1d缓存的信息,以核0为例,在/sys/devices/system/cpu/cpu0/cache目录下有index0~index4这四个目录,分别对应L1d,L1i,L2,L3的信息。我们以L1d(index0)为例查看详细参数。
[root@SH-IDCxxx ~]# cd /sys/devices/system/cpu/cpu0/cache/index0
[root@SH-IDCxxx index0]# ls
coherency_line_size number_of_sets shared_cpu_list size ways_of_associativity
level physical_line_partition shared_cpu_map type
[root@SH-IDCxxx index0]#
[root@SH-IDCxxx index0]# cat level
1
[root@SH-IDCxxx index0]# cat type
Data
[root@SH-IDCxxx index0]# cat size
32K
[root@SH-IDCxxx index0]# cat number_of_sets
64
[root@SH-IDCxxx index0]# cat ways_of_associativity
8
[root@SH-IDCxxx index0]# cat coherency_line_size
64
从图中我们可以知道,这是L1数据缓存的相关信息:共有64个组,每组8行,每行16字(64字节),共有32KB的总容量。按照我们之前的分析,相信你很容易就能说出这个机器上L1d缓存的组织方式。没错,就是8路组相联映射。
此时32位内存地址的拆分如下:
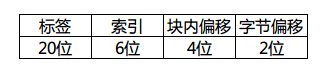
我们继续分析转置问题。每个cache行(块)拥有64个字节,正好是16个int变量的大小。一个n阶矩阵的一个行正好填充n / 16个cache行。512阶矩阵的话,每个矩阵的行就填充在了32个组中,2个矩阵的行就覆盖了64个组。 之后的cache line若要使用, 就必然牵扯到cache的替换了。
如果此时二维数组的array[0][0]开始从cache第一行开始放置。那么当进入第二重for循环之后,由于内存地址计算出的cache组号相同,导致每一个组中的正在使用的cache行发生了替换,不断发生的组内替换使得cache完全没有发挥出效果,所以造成了512×512的矩阵在转置的时候耗时较大的原因。具体的替换点大家可以自行去计算,另外513×513矩阵大家也可以试着去分析没有过多cache失效的原因。不过这个问题是和CPU架构有关的,所以假如你的机器没有产生同样的效果,不妨自己研究研究自己机器的cache结构。
